



Amazon’s Prime Video Tech blog recently released an article that has gotten some internet attention. The article examines a team that was able to reduce their infrastructure cost by up to 90% by moving from a serverless to “monolithic” architecture.
It’s not every day you hear about moving from Serverless to Monolith. So rightfully, this article has gotten quite a few second glances. Some of the takes though are dubious at best claiming “See, even Amazon is saying serverless sucks!”.
That’s…. not what they’re saying it all, and shouldn’t be your main takeaway. So let’s dig into this article and understand why its making such a fuss.
In this post, we’ll examine:
- The problem the team was trying to solve & the initial serverless based approach
- The second iteration that adopted a “monolith” architecture.
- Why going from serverless to “monolith” in this case was the right move
Notice I’m putting monolith in quotes here. More on that in part 3.
If you prefer a video format, check out my YouTube channel on this topic here:
The Problem
For some background, Prime Video is a real time streaming service that offers over 100 channels to watch for Amazon Prime subscribers. The Prime Video Quality and Analysis team wanted to ensure that video streams being served to customers are high quality and free from any video or audio hiccups such as video artifacts (pixelation), audio-video sync issues, and others. The team wanted to develop a mechanism to continuously monitor each stream in the service to automatically evaluate and detect any quality issues.
Initially, the team decided to leverage a previously developed diagnostic tool. This tool primarily leveraged AWS Step Functions, Lambda, and S3 to break apart each stream’s audio/video content into 1 second chunks so they can be more easily managed and evaluated for anomalies.
This tool worked by running continuously against each channel/stream and evaluating it in one second segments. For every segment, a Step Function Workflow was launched. The step function workflow had multiple state transitions which performed extraction, analysis and aggregation steps before saving the results to S3.
For those of you that have worked with Step Functions in the past, you may know that it can get very expensive. The main cost contributor is state transitions. That is, each time your step function moves from one state to another, you’re charged a certain amount.
In Prime Video’s case, a Step Function was being launched every one second for every single stream. This Step Function contained multiple different state transitions to perform its tasks. Ontop of that, intermediary frames and audio buffers were being converted and stored in S3, requiring Lambdas within the step function to continuously make network calls into S3 to grab the relevant data.
There were two main issues with this architecture: cost and scalability.
On the cost side, the number of state transitions and network calls made this architecture infeasible to maintain. Based on my conservative napkin math assessment, the Step Functions cost alone would amount to over $4000 USD per month. Note that this assessment was very conservative due to the lack of detail in the article and the cost was likely much more. This doesn’t even factor in the read and write costs to S3 which would have amplified this number even more.
On the scalability side, Step Functions have two important limits: 1) the number of concurrently running step function workflows, and 2) the number of state transitions per second across all of your state machines. These two limits in combination made it impossible for the solution to scale to the 100+ streams it needed to constantly evaluate. The Prime Video team very quickly hit the maximum concurrency limit and only ended up being able handle 5% of the expected load. Pretty sad.
The diagram below is from the Prime Video article and provides an overview of the architecture and the multiple steps involved in processing a single stream.
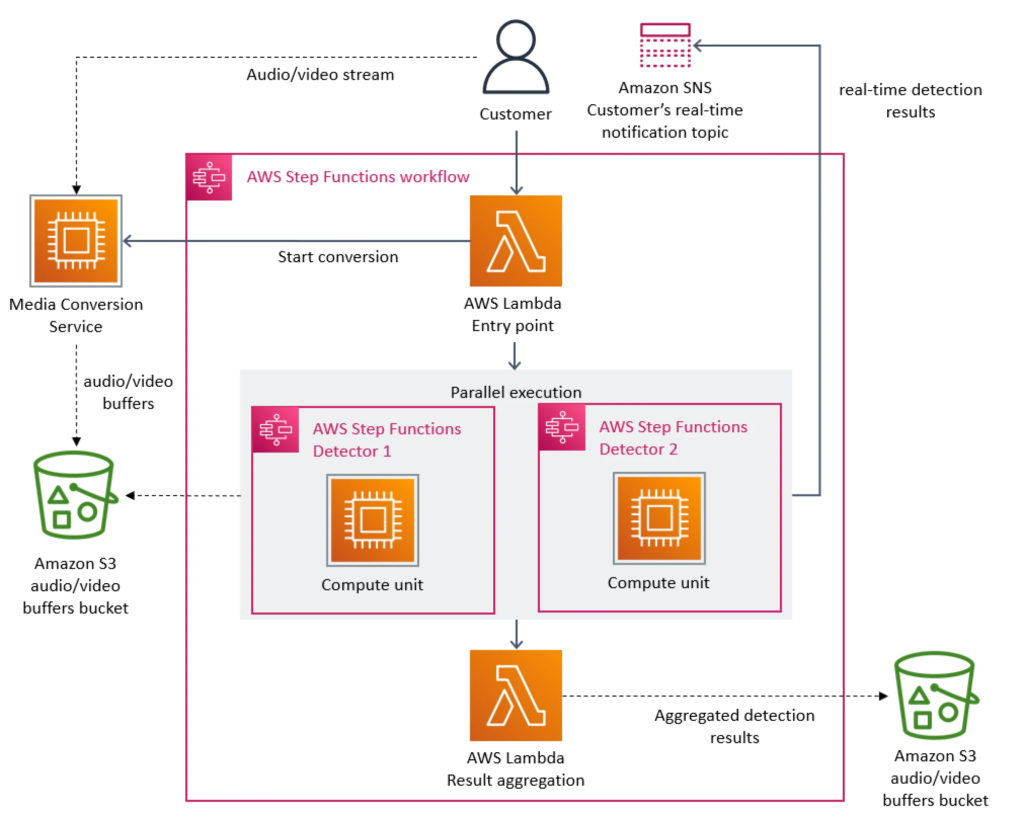
Given these cost and scaling bottlenecks, the team re-evaluated their architecture for something a bit simpler that would optimize for cost & scale by shying away from distributed workload components. Let’s examine that now.
Second Iteration – Designing For Scale
After careful evaluation, the VQA team realized that Step Functions weren’t a good fit for this problem at this particular scale. They decided to opt for a simpler solution that relied on provisioned infrastructure using Elastic Container Service (ECS) as the compute tier.
For intermerdiary storage, S3 was also nixed due to the high cost of making multiple hops (both read and write) to the service. Again, this wasn’t adding much to the overall architecture.
The solution involved running chunk extraction and analysis locally within an ECS task. This way, instead of relying on a Step Function to orchestrate the tasks via a workflow, it was done serially from within a specific ECS task.
The task would first perform the media conversion, and then analyze each 1s chunk by running the content through multiple detectors for quality analysis. Each detector is kind of unique in that it uses a different method to analyze quality issues with the stream.
With this architecture, intermediary data no longer needed to be stored in S3 and fetched at a particular point in the workflow. It was all being stored locally in memory on the ECS task and used/discarded as needed. This, ontop of moving away from Step Functions really helped drive down the costs of running the service.
Finally, after the detectors performed their task on a chunk of content, results for each detector were aggregated in the ECS task and saved to S3 using one write operation.
A diagram of the revised architecture can be seen below:
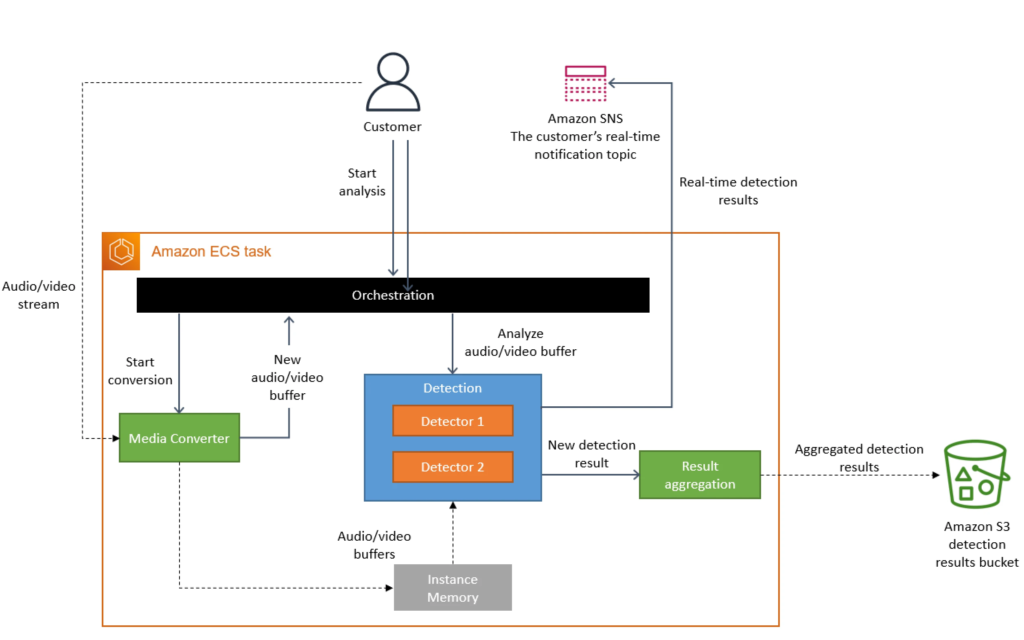
A keen observer may notice that this architecture carries a scaling bottleneck with the detectors component. Imagine that the PV team wants to leverage some new method to detect audio/video degradation. In this architecture, that would mean adding one more detector and serially running it (in addition to the other ones) for each chunk of content.
If there are too many detectors to be run for a single task, the duration it takes to run the content through the multiple detectors will increase. If too many are added and the sum of operations across the detectors exceeds 1 second (the chunk parsing rate), the entire workflow will begin falling behind and not be able to recover.
In the Prime Video case, there really was a need for multiple detectors but falling behind on processing wasn’t an option. To mitigate this, the team decided to paramaterize each ECS task so that each one was dedicated to running a handful of the detectors. Then, the team could launch multiple ECS tasks in parallel with each task only executing a couple of the detectors. This allowed them to horizontally scale by breaking apart the workload into separate units and run them concurrently.
The revised architecture looked like this:
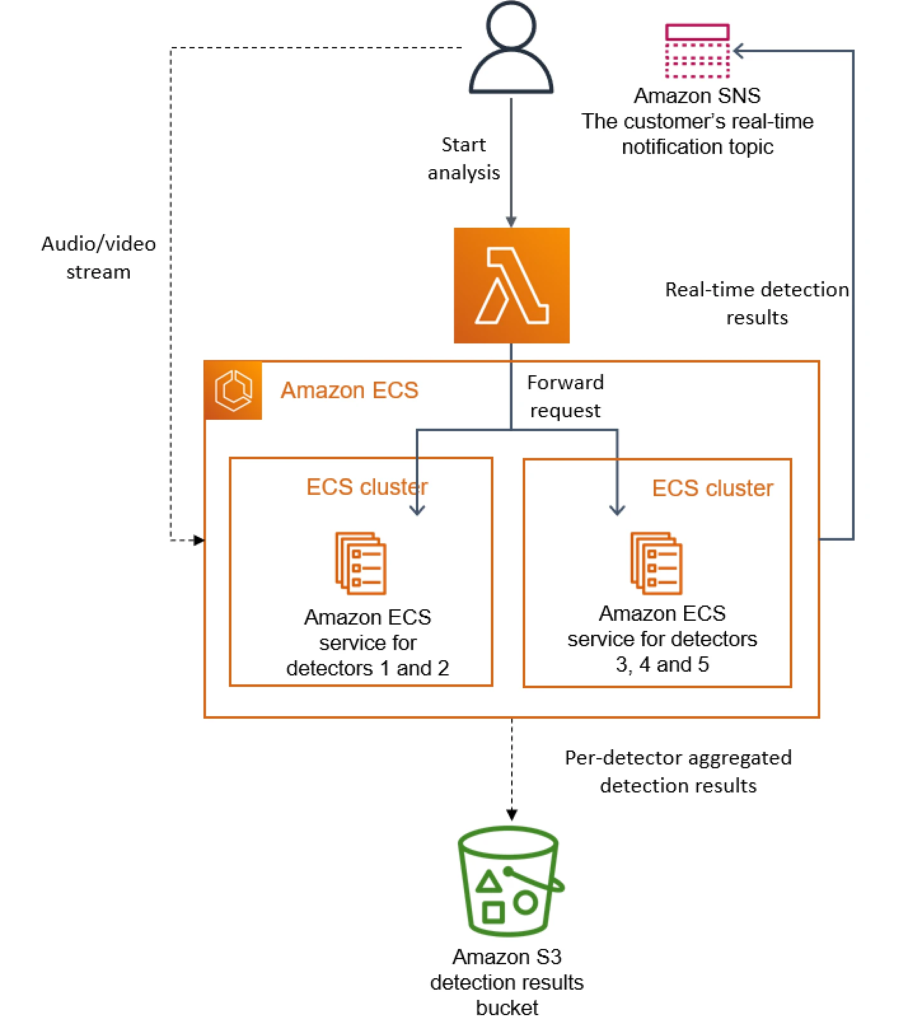
By using this revised architecture, the PV team now had a scalable and cost effective solution to monitor their feeds. All in all, they were able to save 90% of their costs when compared with the initial serverless iteration.
So that’s the story that took the internet by storm. But why is everyone freaking out? Is this move from serverless to monolith a new trend of the industry? Should serverless lovers be worried? I say no, for reasons laid out in the next section.
Why Going From Serverless to “Monolith” Was The Right Move
First things first, this architecture is not a monolith and this is part of the reason the internet is angry. When I think of a monolith, I think of a giant service that has many different responsibilities. Maybe it has APIs, SQS pollers, does multiple things for different use cases, you get the picture. But is the architecture laid out above a monolith? Hardly. It’s a small microservice for heaven’s sake! So right off the bat, the whole fuss folks are making about monoliths coming back into style is a moot point.
Secondly, the original architecture was based on a tool that was not designed for scale. Based on the article, it read as if this tool was used for diagnostics to perform ad-hoc assessments of stream quality. This means it likely wasn’t designed for scale or put through the pressure tests of a formal design document / review. If that were to happen, any run of the mill Software Engineer would have been able to recognize the obvious scaling / cost bottlenecks that would be encountered.
Finally, I think the PV team made all the right moves by switching to provisioned infratructure. They identified an existing tool that could have been a potential solution. They attempted to leverage it before realizing it had some real scaling / cost bottlenecks. After assessing the situation, they pivoted and re-designed for a more robust solution that happened to use provisioned infrastructure. This is what the software development process is all about.
In terms of the whole Serverless vs Monolith/Microservice debate — why are we still having this argument in 2023? Serverless isn’t a catch-all that is ideal for every single problem, and the same applies for monoliths or provisioned infrastructure. Both have a place and its up to us to pick the right tool for the job.
If you’re a developer building modern cloud based applications, remember to carefully analyze the characteristics of your workload and decide on an infrastructure that best fits. Don’t get pigeon holed into using a particular infrastructure or technique just because its popular – pick what makes sense and is applicable for your use case.
So that’s my rant. I’m eager to hear what other folks think of the article and the internet debate that ensued. Let me know what you think in the comments below.


