




This post is going to explore the difference between Amazon Aurora Serverless V1 and V2. We’re going to briefly touch on the shortcomings of Aurora V1. Then, we’ll explore what V2 has to offer and the improvements it provides over V1.
What is Aurora Serverless V2?
AWS just announced the general availability of Aurora Serverless V2. V2 is afully Serverless and instant scaling RDS database designed for high throughput and latency sensitive production workloads.
You may be thinking to yourself, hasn’t Aurora Serverless been around for a while? And it has – the initial version of Aurora Serverless, also called V1, was launched in 2018. It offered a simple, scalable, cost-effective, and highly available Serverless database that’s compatible with MySQL and Postgres. However, V1 was not aimed at production use cases. Instead, it was more tailored for infrequent access applications such as development environments. V1 suffered from a bunch of problems such as slow and choppy scaling that prevented it from becoming a reliable database for production scenarios.
Let’s now explore one of the major improvements Aurora Serverless V2 has made – scaling.
How Aurora Serverless V2 Scales
Serverless V2 offers a faster and more reliable scaling mechanic when compared to V1. In fact, it addresses most of the concerns of V1 and adds even more useful features. What makes V2 special compared to V1 is that it can scale up and down almost instantly from hundreds of transactions per second to hundreds of thousands. V2 also continues to leverage the decoupled compute and storage architecture that makes Aurora so popular.
Here’s a quick reminder of how storage scaling works. Storage is handled automatically for you. This means Aurora will automatically make available more GBs of storage if your cluster requires it – no more copying over instances from a smaller to a larger size to perform an upgrade.
The compute portion of the database is handled by different machines, each being able to vertically scale themselves up in the forms of ACUs or Aurora Capacity Units. According to AWS, each ACU that Aurora provisions roughly translates to 2 GB of memory, corresponding CPU and networking.
Based on how hard your database is working in terms of throughput, Aurora will scale ACUs up or down. Each step offers more compute and memory on the instance. Previously with V1, step-wise scaling would take place at 1 ACU increments and only when the database could find a scaling point – a moment in time when Aurora is performing no transactions. This made it harder for V1 to promptly scale up your compute to match your demand. It often meant overshooting and undershooting as your demand fluctuates. As you could imagine, lack of rapid scaling in V1 meant that Aurora could not keep up with emergent demand on your database. This lead to poor performance.
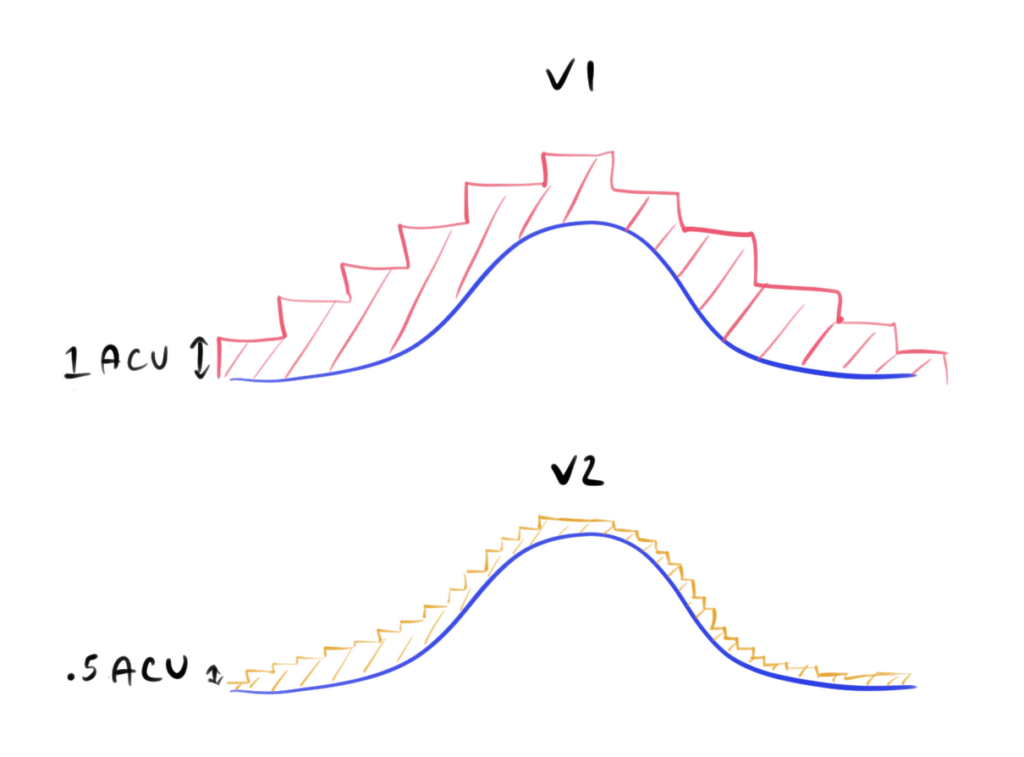
This diagram illustrates the problem. Blue is a typical customer workload, quiet in the evening with a steady upswing that peaks in the afternoon before starting to fall once more. The red line is the “steps” that aurora scales up or down at. And this is the effective problem with Aurora V1 – steps are tall and the gap between actual usage and provisioned usage is wasted money for you – the user. The hatched area illustrates the wasted capacity.
V2 improves in this by making steps smaller and faster to respond to demand fluctuation. Steps are now taken in .5 ACU increments and occur quicker. This allows Aurora Serverless V2 to more easily match compute capacity with actual demand. In the long run, this saves you money.
You can currently scale up to a maximum of 128 ACUs for both MySQL and Postgres compatible variants. This makes it perfect for workloads that require both very low or very high performance profiles.
More Aurora Serverless V2 Features
Aurora Serverless V2 also adds more features that bring it towards parity with the provisioned Aurora model. You now have access to Multi-AZ clusters. This means you can spread out your replicas across availability zones to increase your database’s availability. You can add up to 15 read replicas to distribute your workload, with each read-replica being able to independently scale up or down based on demand.
Other notable features include support for Global Databases and IAM based authentication. IAM auth is a particularly interesting one – it allows you to use your AWS credentials (aka access and secret key) to acquire temporary access to your database. This makes it easier to manage access to your cluster and saves you from the headache that comes from having to change your database’s password.
Drawbacks
Aurora Serverless V2 isn’t perfect. Here are some of the drawbacks of using it that you should be aware of.
Scaling
One of the unfortunate parts of using V2 is that it cannot scale down to 0 ACUs. The minimum ACU threshold is .5 units. This is different than V1 where the database could scale down to zero – effectively costing you zero dollars while the database is not in use. You can manually stop your Aurora V2 database through a CLI command or through the console. This will bring down the ACUs to zero. But this defeats the purpose of serverless, doesn’t it? I don’t recommend going with this approach but it may be viable
For whatever reason, Aurora Serverless V2 changed this minimum. This means you have a minimum cost for using Serverless V2 even when your database is not serving any traffic. This is certainly not ideal, but its the price to pay for instantly scaling on demand capacity.
No Data API
One of the most unfortunate discoveries of Aurora Serverless V2 is that it does not support the Data API. The Data API is an incredible feature that allows you to perform queries on your database through a REST API. This is in contrast to the traditional method of connecting to a jdbc endpoint and running your queries directly via the database connection.
Unfortunately, V2 does not currently support the Data API. I fully expect this to be a temporary shortcoming of V2 given Data APIs popularity. However its an important consideration to be aware of if you’re already a fond user of it.
Summary
Amazon Aurora Serverless V2 is a significant step up over V1. It makes Aurora Serverless a viable option for users looking for a Serverless RDS database that is capable of instantly scaling to hundreds of thousands of transactions per second. It adds a bunch of additional features including IAM based authentication, read replicas, global databases, and many more features. You can read about the full comparison of features between V1 and V2 here.
Serverless V2 does not come without its drawbacks though. Specifically in the domain of minimum scaling. You now need to keep your database effectively “warm” and provisioned with .5 ACUs. This can add some unneccessary cost to your billing but isn’t a deal breaker in my opinion.
Additionally, you can’t use the Data API (yet). This isn’t a huge deal for me but it could be for some. I’m hoping the AWS team works to add support by the end of 2022.




Would you consider Amazon Aurora Serverless v2 ready for production use like a online shopping website?
Absolutely – in fact I think the whole release of V2 was to make it production viable. Careful of the minimum ACU cost though!
How to connect aurora serverless v2 postgres using pg client or any other library in lambda?