




On June 13th, 2023, customers using AWS Lambda abruptly started seeing increased error rates and higher than normal latencies. These issues caused customer applications to begin failing, but they also affected a number of other AWS services that use Lambda under the hood — services like ECS, AppRunner and Cloudwatch. And you would think as a result of these issues, AWS service health dashboard would light up like a christmas tree—but it didn’t, cause it turns out the service health dashboard also has a dependency on Lambda (womp womp).
This was one outage that happened to have a large impact – and if you take a look at AWS’ post-event summaries website, you’ll notice there’s a whole lot more of these types of events. But each one, despite looking like a failure, offers a unique opportunity. An opportunity to deeply analyze the series of events that led up to the incident and institute changes that prevent them from ever happening again.
Embracing failure and seeing it as a learning opportunity is how companies like Amazon almost never make the same mistake twice. And the key lies in a structured process to document these events from beginning to end, while also analyzing impact, response procedures, root cause, and more. All of these details are included in a formal document that Amazon appropriately called a Correction of Error or CoE document.
The remainder of this article is about this unique culture of embracing failure through this Correction of Error document and process. And what makes me qualified to talk about any of this? Well, I’ve worked at Amazon for over a decade now and fortunately or unfortunately, I’ve authored a fair share of CoEs myself — each one being painful but also a satisfying accomplishment. And I can tell you with 100% certainty that if you embrace this culture of writing CoEs in your organization, you’ll not only see repeat errors less often, but you’ll change the entire way you look at outages to be something to learn from instead of something to be ashamed of.
Now, I want to explain to you exactly what a CoE document looks like and provide you a template you can use to get started with your own. But despite Amazon’s CoE process being publicly documented and well known, there aren’t any high quality publicly available examples that give you an idea on what this document should actually contain and how it should be written. So not only am I going to provide you a template for writing your own CoE, and share with you an example CoE that I specifically wrote for you for this article. This CoE contains all elements I would expect to see in a CoE written inside Amazon, and I hope it gives you an idea of the quality you should strive for. If you want to get both the example I’m about to show and a template you can use to write your own, check out form at the bottom of this article.
But before we get into that, lets briefly touch on a two important areas:
- What is a CoE document?
- Benefits of writing a CoE document
What is a CoE Document?
A CoE is a 4-6 page written document that extensively analyzes a technical issue that led to significant customer impact. It contains the following key components:
- Title – The title is less than twenty words long and briefly describes the issue and impact.
- Summary – The summary section is the first thing a reader sees. It contains context for the event, how the event was discovered, a brief description of the impact, and what was or is still being done about it. It shouldn’t go into too much detail about any specific area here, but should give a good enough overview that a reader can have a firm grasp on the issue before deciding to read any further.
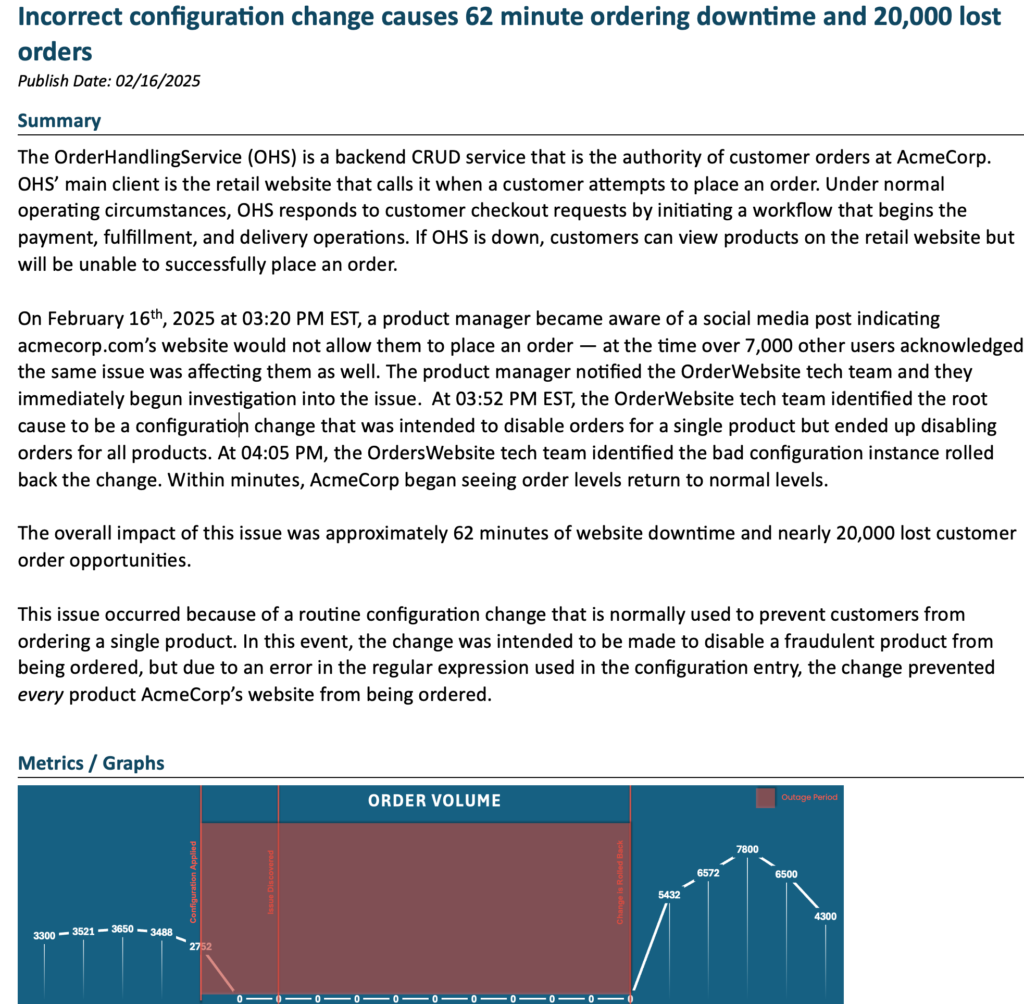
- Metrics / Graphs – the metrics / graphs section provide helpful context on the lead up to the event, the impact of it, and the recovery. There’s no specific rule of how many graphs you should include, but you need at least one or two but don’t have too many where it becomes overwhelming. Less is more here and try to only show what matters. Another thing thats common in this section is to include vertical lines with short description that indicate key events relating to the outage. This helps the reader understand the timeline and when certain things happened.
- Impact – the impact section describes the total customer impact and the duration of the event. The section itself contains a bunch of pre-established questions that you need to answer.
- Incident Response – the incident response covers how you became aware of the issue (customer or automated) and how you responded to it. This section contains a bunch of pre-established questions that you need to answer.
- Timeline – the timeline is a list of chronological events that relate to the issue. One side note here – you may be wondering how do I re-create the timeline for an event well after the event actually happened? Well this is why its important to have some kind of collaboration tool during high severity events to document what is happening and when. Not having this audit trail that you can analyze later will make it very difficult if not impossible to re-create the timeline.
- 5 Why’s – the 5 why’s is one of the most important sections of the entire document. It attempts to drill down into the issue, starting from the impact, to determine the root cause. You start by asking “why did X happen”? which leads to an answer. You then ask why did THAT happen, which leads to another answer. You keep asking questions and answering them and eventually, you’ll get to the point where there’s no more questions to answer, and that will be the point you identified the root cause.
The reason we call it “5 why’s” is because usually it takes no more than 5 rounds of questions and answers to get to the root cause. Keep in mind though that there can be a single question that has multiple answers that need to be explained. In these situations its common for folks to create parallel branches of questions and answers. - Action Items – After you discovered your root cause or causes, you can then define your action items. Each action item should be labelled with a title, severity, due date, and more. The Action Items section is the final section of the document. You should ideally have this document hosted in a public place like a network or google drive folder that folks can refer to later. As you complete action items, you should update the document and inform your stakeholders that mitigation is in place.
Here is what an example CoE looks like (custom written by me for this article).
There are a couple more steps to this process that aren’t part of the document itself but helpful in the CoE exercise.
Publish your CoE – The final step after the leadership review is to publish your CoE. This usually involves hosting it in a company-accessible location and sending out an email to tech teams to inform them. If your CoE gleaned any key insight that could affect other teams using the same technology of your company, you should include those insights as well. This is a great way to broadcast your hard work and allow other teams to benefit from your findings to prevent similar issues.
One small piece of side advice on this topic. One of the best thing’s I’ve done in my career to enhance my engineering knowledge is to actively pursue and read other team’s CoEs. The breadth of issues you’ll see and variety of interesting failure modes you never even thought were possible help broaden your knowledge and help you avoid similar types of issues going forward. Do yourself a favour and start reading other team’s CoEs – you’ll become a much better engineer in the long run.
Team Review – After you complete your document, you should schedule an internal team review. During this review you collect feedback from your team on the CoE content and improve it iteratively.
Leadership Review – Finally, after your document has been reviewed with your team, you go up a chain and review it with your tech leadership. This can be your sr. manager, director, VP, or CTO — it highly depends on the structure and size of your company. You really want to make sure your document is polished and doesn’t have any content or grammatical mistakes. This is a usually the highest pressure part of the entire process. Read your document as if your an outsider that limited context into the system to ensure the material can be understood. Anticipate questions that the reader might have and practice responding to them. You really don’t want to look like a fool in these meetings.
Who writes the CoE?
You may be wondering, if an event occurs, who is responsible for writing the CoE? Most often, CoEs are written by a single team including one assigned engineer and their manager. The engineer is usually the one that was responsible for the underlying issue. The engineer drives the content collection, first drafts, and action items, while the manager provides key inputs and revises / edits the content as needed. There isn’t a fine line that defines who does what, so the two should work together to ensure the document is as high quality as possible.
For larger issues that span across many teams, it may make more sense to have a joint CoE. Even though the CoE is joint, a single owner should take responsibility for the document and drive coordination across all involved teams.
A couple more important things to know about CoEs
Now another obvious question, when should you write a CoE and when should you not? There is no precise formula that answers this question, but usually the determinant is based upon the impact. If the issue caused a high level of impact to your customers, write the CoE. If the impact was relatively small, then a CoE may be overkill and not be a good use of your time.
Sometimes there are issues that have high technical impact on the systems you own but don’t necessarily translate int perceivable impact for your customers. An example could be a feature release with a implementation flaw that looked like it was working correctly from an outside perspective, but internally there were issues. In cases like this one, you should consider writing an internal CoE. This is the same document as we discussed before, but quality perfection isn’t a priority — its more about documenting the issue, identifying action items, and developing mechanisms to ensure it doesn’t happen again. It goes without saying for internal CoEs, you don’t need to do a leadership review, and you don’t publicly broadcast it to all other teams in the company – this type of CoE stays within your team.
A couple other key things to remember about CoEs:
- They are not a punishment – CoEs should be treated as a constructive process that helps resolve the root cause of high impact issues . If you cause a CoE and have to write one-don’t panic, the best thing to do is to completely own it. This means being self-critical of mistakes with a focus on improvement and preventing the issue going forward. The worst thing you can do is get into a blame game since it defeats the entire purpose of the document. I’ve actually seen CoE documents been used as artifacts for engineer’s promotion documents, so please don’t treat them as bad things.
- Don’t refer to actors by name – since a CoE is NOT about blaming and meant to be constructive, you never mention a particular person by their name. If sally from your team caused an event, you simply say “An engineer from XYZ team”, or a “Product manager from ABC team”. Never specify the people and simply refer to them in abstract. Similarly, always use the third person when writing the document. There should never be i’s or we’s.
- CoEs are after the fact mechanisms – During a high impact event, the highest priority is mitigating customer impact. Don’t worry about the CoE at the time, that will come later. Instead spend your energy trying to prevent further damage to your customer’s experience. Root cause analysis and preventative measures come in the days and weeks that follow during the CoE writing process.
- CoEs WILL affect your product development roadmap – A lot of effort goes into both writing your CoE and completing action items. This means your engineering team’s roadmap will need to adjust to ensure there are enough resources assigned to complete action items. This also means that projects you may have committed to prior in the year may need to be de-prioritized. De-prioritizing projects means your product partners may get frustrated, do not buckle. CoE action items for high impact events are sacrosanct – they should always be prioritized over any product feature. This can be a tough pill to swallow for both engineering manager’s and leadership. But a CoE is not something to be taken lightly – it is a commitment . The best CoE is a CoE that is never written. This means you need to prioritize thinking about mechanisms to ensure high quality software including unit & integration tests, configuration change automation, group design documents, and more.
Now that we have a good understanding of what CoE’s are, lets briefly touch on some of the benefits of adopting CoEs into your company’s culture.
Benefits of Writing a CoE document
There are three main benefits of writing a CoE document:
1 – Company Wide Improvement – Root cause analysis for a CoE can lead to key insights that a company may not have otherwise discovered. These types of issues, especially when they relate to a technology that is widely used across the company, can have exponential benefits. However, insights gained are only as valuable if they are shared with, read by, and responded to by other teams. This means some CoE action items may necessitate a company-wide campaign to address. The idea is that it is better to expend company-wide effort to proactively address an issue than risk another high impact customer event and resulting CoE. Never make the same mistake twice.
2 – Root Cause Analysis and Future Issue Prevention – The biggest benefit of writing a CoE is the confidence you’ll have that the same issue will likely never happen again. This assumes that the action items you’ve come up with – either software changes or process adjustments – were well thought out, completed, and up-held. The act of writing a CoE and the action items that follow should create a culture change for your team that focuses on proactive failure analysis and edge case anticipation. Lean into this culture change and embrace it.
3 – Record of Past Issues – As a company grows, it can difficult to keep track of issues across teams. CoEs give you a comprehensive record of past issues at a company that you can refer to over and over again. This assumes you keep your CoEs in a company-wide accessible location – ideally one that indexes their content to make it easily searchable.
Next Steps
Did I convince you CoEs are worthwhile? I hope so. If you’d like to read a REAL example of a CoE and also get access to a template file to create your own, fill in the form below.




awesome